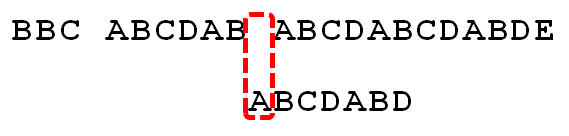
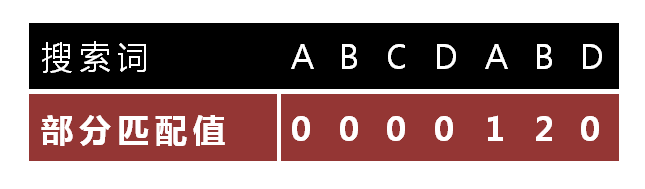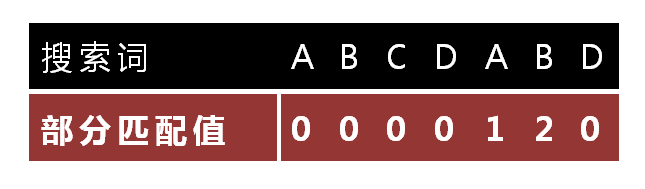shell命令解析输入字符串的默认分割符是水平制表符(tab),空格(space)和换行(newline)
要改变当前shell的默认分割符,用IFS的环境变量。
- 默认的分割符
1
2
3[root@centos01 tmp]# echo -n "$IFS" | hexdump
0000000 0920 000a
0000003
十六进制值0x20, 0x09和0x0a分别对应于空格(space), 水平制表符(tab)和换行符(newline)的值。
- 下面两个方法的运行结果直接说明问题:
1 | #!/bin/sh |
运行结果
1 | [root@centos01 tmp]# ./test.sh |